
Introduction
Cybersecurity has become one of the most critical issues of the digital age. With technological advancements and the widespread use of the internet, the diversity and complexity of cyber threats have also increased. Traditional security systems are becoming increasingly insufficient against these constantly evolving threats, while machine learning technology emerges as a promising solution. With its ability to learn from large datasets and recognize complex patterns, machine learning has the potential to revolutionize cybersecurity applications. It not only identifies existing threats but also provides proactive defense by predicting potential future dangers. This article explores how machine learning can be used in cybersecurity, specifically through network traffic analysis and anomaly detection. It thoroughly examines the collection and processing of network traffic data and how machine learning models can be used to detect anomalies.
The Importance of Machine Learning in Cybersecurity
Machine learning is gaining increasing importance in the field of cybersecurity. This technology has the ability to adapt to continuously changing threat landscapes and enhance the effectiveness of security systems. As cyber attacks become more complex and sophisticated, traditional security methods can become inadequate. Here, machine learning comes into play; it can analyze large datasets, recognize patterns, and detect potential threats in real-time. This article will examine how anomalies can be detected using network traffic analysis and machine learning.
Network Traffic Analysis and Anomaly Detection
Network traffic analysis is the process of examining the data passing through a network. This analysis is critical for monitoring network performance, understanding user behaviors, and detecting security threats. Anomaly detection, on the other hand, is the process of identifying behaviors that deviate from the norm. Anomalies in network traffic can indicate malicious activities or system faults. In this study, we will demonstrate how to detect anomalies by listening to network traffic data, processing this data, and using machine learning models.
Purpose and Scope of the Article
The purpose of this article is to explain step-by-step processes of collecting network traffic data, data preprocessing, and anomaly detection using machine learning models. First, we will go through a Python script that shows how network traffic data can be collected and processed. Then, we will discuss how this data can be used in a machine learning model and what approach can be followed for anomaly detection.
Network Traffic Data Collection
Code Example: listener.py Script
The first step in collecting network traffic data is to listen to the packets passing through the network. For this task, we prepared a script using Python’s Scapy library. Scapy is a powerful tool for capturing and analyzing network packets. The following listener.py script listens to a certain number of IP packets and collects their basic information:
from scapy.all import sniff, Ether, IP, TCP, UDP
import csv
def packet_analysis(packet):
packet_info = {
'mac_src': '', 'mac_dst': '',
'ip_src': '', 'ip_dst': '',
'length': 0, 'protocol': 0,
'port_src': '', 'port_dst': '',
'tcp_flags': '', 'tcp_window_size': ''
}
if Ether in packet:
packet_info['mac_src'] = packet[Ether].src
packet_info['mac_dst'] = packet[Ether].dst
if IP in packet:
packet_info['ip_src'] = packet[IP].src
packet_info['ip_dst'] = packet[IP].dst
packet_info['protocol'] = packet[IP].proto
packet_info['length'] = len(packet)
if TCP in packet:
packet_info['port_src'] = packet[TCP].sport
packet_info['port_dst'] = packet[TCP].dport
packet_info['tcp_flags'] = str(packet[TCP].flags)
packet_info['tcp_window_size'] = packet[TCP].window
elif UDP in packet:
packet_info['port_src'] = packet[UDP].sport
packet_info['port_dst'] = packet[UDP].dport
return packet_info
packets = sniff(count=100000, filter="ip", prn=lambda x: x.summary())
packet_data = [packet_analysis(packet) for packet in packets if IP in packet]
with open('network_data.csv', 'w', newline='') as file:
dict_writer = csv.DictWriter(file, fieldnames=packet_info.keys())
dict_writer.writeheader()
dict_writer.writerows(packet_data)This script extracts information such as MAC addresses, IP addresses, protocol details, and other details from each packet and writes them to a CSV file.
Scapy’s Network Packet Listening Capabilities
Scapy is a Python-based network tool known for its abilities to manipulate, send, and listen to network packets. This script uses Scapy’s sniff function to listen to network traffic. This function captures a specified number of packets (count=100000) applying a particular filter (filter="ip").
Packet Analysis Process and Types of Collected Data
Each captured packet is sent to the packet_analysis function. This function extracts information from the Ether, IP, TCP, and UDP layers of the packet and stores it in a dictionary structure. The collected information includes source and destination MAC addresses, IP addresses, packet length, protocol type, source and destination port numbers, TCP flags, and TCP window size.
This data will later be used as the foundational dataset for training the machine learning model and detecting anomalies.
Data Preprocessing
Data preprocessing is a vital step in machine learning projects. This process involves transforming raw data into a format that can be processed by the model. Network traffic data is often complex and varied, so properly preparing this data can significantly impact the model’s accuracy and performance.
Code Example: Reading Data and Preprocessing Steps
In our analiz.py script, we first use the pandas library to read the CSV file. We then apply Label Encoding and One-Hot Encoding techniques to convert categorical data in the dataset into a numerical format. We fill in missing data with -1. These steps prepare the dataset to be processed by the machine learning model:
import pandas as pd
from sklearn.preprocessing import LabelEncoder, One-HotEncoder
# Load data
df = pd.read_csv('network_data.csv')
# Label Encoding for IP and MAC addresses
labelencoder = LabelEncoder()
for column in ['mac_src', 'mac_dst', 'ip_src', 'ip_dst']:
df[column] = labelencoder.fit_transform(df[column])
# One-Hot Encoding for TCP Flags
df = pd.get_dummies(df, columns=['tcp_flags'], prefix=['flag'])
# Replace missing values with -1
df.fillna(-1, inplace=True)Label Encoding and One-Hot Encoding Methods
Label Encoding converts categorical data into numerical labels. This method assigns a unique number to each unique categorical value. On the other hand, One-Hot Encoding creates a separate column for each categorical value and assigns a value of 1 in the relevant column and 0 in others. These techniques allow the model to process categorical data more effectively.
Isolation Forest Algorithm
Reasons for Choosing Isolation Forest for Anomaly Detection
The Isolation Forest algorithm is specifically designed for anomaly detection. This method is based on isolating anomalies in the data and can work effectively in high-dimensional datasets. Since abnormal behaviors are usually in the minority, Isolation Forest can isolate these minority samples faster than normal ones.
Code Example: Training the Isolation Forest Model
We use the Scikit-learn library’s implementation of Isolation Forest to train our model. We apply the model to the entire dataset for training and perform anomaly predictions:
from sklearn.ensemble import Isolation Forest
# Isolation Forest Model
model = Isolation Forest(n_estimators=100, contamination=0.01)
model.fit(df)
# Anomaly Prediction
df['anomaly'] = model.predict(df)The Fundamental Principles of the Algorithm
The Isolation Forest works by isolating data points in a tree structure. Anomalous data points are usually isolated with fewer splits, making them easier to detect. The n_estimators parameter determines the number of trees to be created, while the contamination parameter is used to estimate the proportion of anomalies in the dataset.
Anomaly Predictions and Analysis of Results
After the model is trained and anomaly predictions are made, the analysis of these predictions becomes important. In our analiz.py script, the anomalies predicted by the model are added to the dataset as an ‘anomaly’ column. Data points marked as anomalies can indicate potential security threats or network performance issues. The analysis of these results can provide valuable insights to network security experts:
# Anomaly Prediction
df['anomaly'] = model.predict(df)
# Filter Anomalies
anomalies = df[df['anomaly'] == -1]
print(anomalies)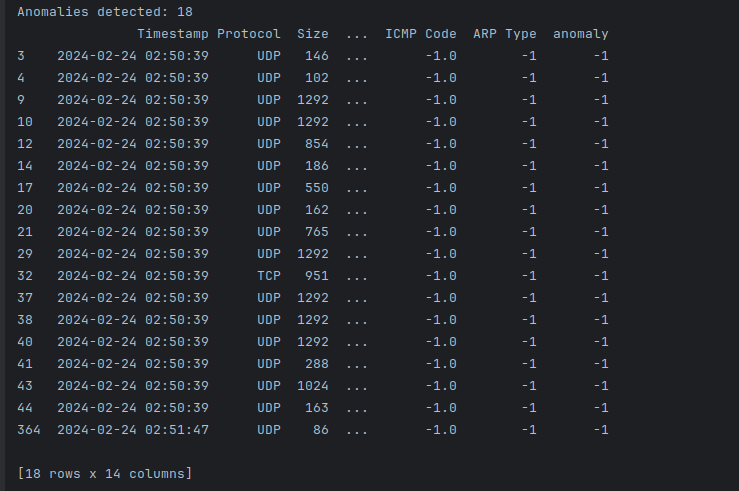
Challenges in Anomaly Detection and Methods to Overcome These Challenges
One of the biggest challenges in anomaly detection is balancing false positives (normal situations mistakenly marked as abnormal) and false negatives (missing abnormal situations). To achieve this balance, careful adjustment of the model’s hyperparameters (e.g., contamination) is necessary. Also, regularly updating and training the model with new datasets helps it adapt to changing network conditions.
These sources provide additional information on the topics addressed in the article and deepen the understanding of this field. Also, the contributions of Victor Ahgren have played a significant role in the development of this project.
Conclusion
This article has thoroughly examined the steps of detecting anomalies using network traffic analysis and machine learning, through the listener.py and analiz.py scripts. The processes of data collection, preprocessing, model training, and anomaly predictions have been discussed. The Isolation Forest algorithm has emerged as an effective approach for anomaly detection.
- Victor Ahgren: We thank Victor Ahgren for his significant contribution to the development of the codes used in this project. Victor’s LinkedIn profile provides more information about his areas of expertise and professional contributions.
- LinkedIn: Victor Ahgren on LinkedIn