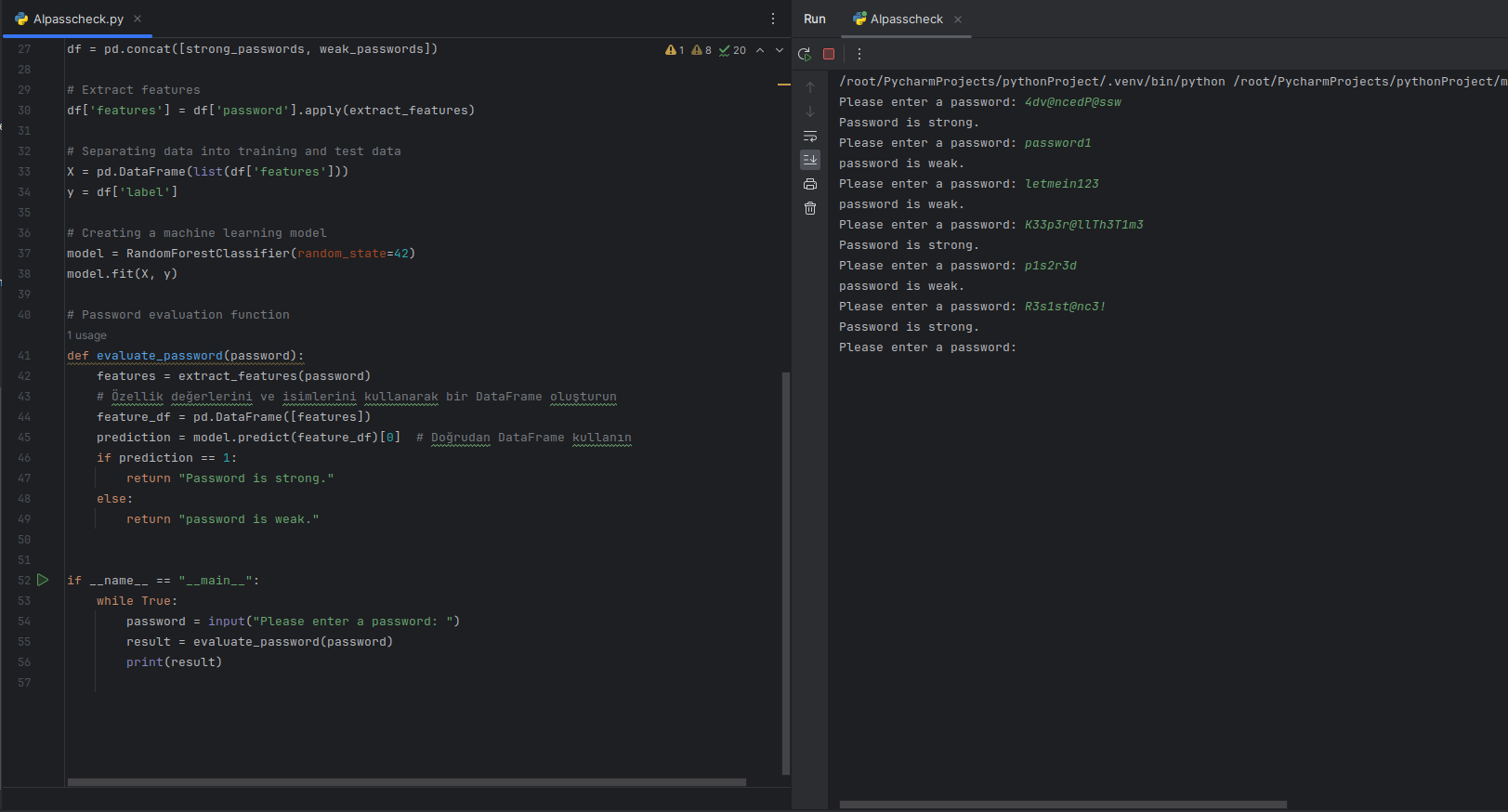
In the digital age, password security is a crucial aspect of protecting personal and sensitive information. Traditional methods of password validation often rely on predetermined rules, such as minimum length or the inclusion of various character types. However, these methods can be insufficient in determining the true strength of a password. To address this challenge, we turn to machine learning (ML) python as an innovative solution. In this article, we present a Python script that leverages ML techniques to evaluate password strength.
The Approach
The core idea is to train a machine learning model that can differentiate between strong and weak passwords. Our script uses Python’s popular libraries, including Pandas for data handling, Scikit-learn for machine learning, and re (regular expressions) for feature extraction.
Data Preparation
We start by collecting a dataset of passwords labeled as either ‘strong’ or ‘weak’. This dataset is stored in two separate text files: strong_passwords.txt and weak_passwords.txt. Each line in these files contains a password, classified according to its strength. to download data
Feature Extraction
The next step involves extracting features from these passwords. Features include password length, presence of uppercase and lowercase letters, digits, and special characters. These features capture the essential characteristics that typically influence a password’s strength.
Model Training
For our model, we chose the RandomForestClassifier from Scikit-learn due to its robustness and ability to handle non-linear data. The dataset is split into training and testing sets, and the model is trained on the former.
Code Snippet
Here’s a snippet of the program:
1. Importing Libraries and Feature Extraction Function
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import re
def extract_features(password):
""" Function to extract features from a password """
length = len(password)
has_upper = any(char.isupper() for char in password)
has_lower = any(char.islower() for char in password)
has_digit = any(char.isdigit() for char in password)
has_special = bool(re.search(r'[^a-zA-Z0-9]', password))
return [length, has_upper, has_lower, has_digit, has_special]- Libraries: This imports necessary libraries like Pandas for data handling, scikit-learn for machine learning, and re (regular expressions) for special character detection.
- Feature Extraction: The
extract_featuresfunction is used to extract characteristics from passwords, including length, presence of uppercase and lowercase letters, digits, and special characters.
2. Data Reading and Dataset Creation
# Read data from files
with open('strong_passwords.txt', 'r') as file:
strong_pass = file.read().splitlines()
with open('weak_passwords.txt', 'r') as file:
weak_pass = file.read().splitlines()
# Create the dataset
data = pd.DataFrame({
'password': strong_pass + weak_pass,
'security_level': [1] * len(strong_pass) + [0] * len(weak_pass)
})- Data Reading: Passwords are read from ‘strong_passwords.txt’ and ‘weak_passwords.txt’ files.
- Dataset Creation: A pandas DataFrame is created using the passwords and their security levels (strong = 1, weak = 0).
3. Feature Extraction and Dataset Splitting
# Feature extraction
features = data['password'].apply(lambda x: extract_features(x))
X = pd.DataFrame(list(features), columns=['length', 'has_upper', 'has_lower', 'has_digit', 'has_special'])
y = data['security_level']
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)- Feature Extraction: Features are extracted from each password.
- Training and Testing Split: The dataset is divided into a training set for training the model, and a test set for evaluating the model’s performance.
4. Model Training and Evaluation
# Train the model
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
# Evaluate the model's performance
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f'Model Accuracy: {accuracy * 100:.2f}%')- Model Training: The RandomForestClassifier model is trained with the training data.
- Model Evaluation: The accuracy of the model is measured using predictions made on the test set.
5. User Interaction
# Get password input from the user and use the same DataFrame structure
user_password = input("Enter your password: ")
user_features = pd.DataFrame([extract_features(user_password)], columns=X_train.columns)
prediction = model.predict(user_features)
print('Secure Password' if prediction[0] == 1 else 'Weak Password')- User Password Input: The script prompts the user to enter a password.
- Password Evaluation: Features of the entered password are extracted, and the model uses these to classify the password as strong or weak.
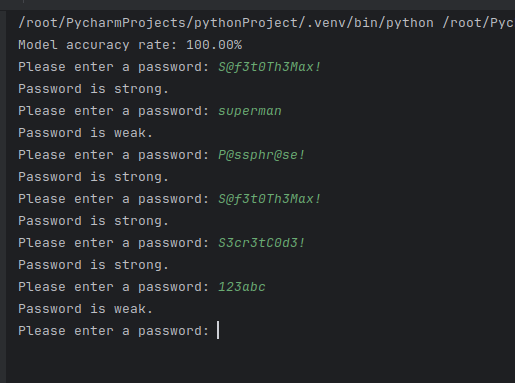
This detailed breakdown clarifies each step of the code and helps readers understand how the process works.
User Interaction
After training, the script can evaluate any password entered by a user. Using the trained model, it predicts whether the password is strong or weak, aiding users in making more secure choices.
Conclusion
This Python script demonstrates the potential of machine learning in enhancing cybersecurity measures. By moving beyond traditional rule-based validation, we can provide a more nuanced and effective assessment of password strength. As cyber threats evolve, such innovative approaches will be pivotal in safeguarding digital security.
thank you for your amazing projects
Kyler Morrison
Cade Richard
+1
I don’t even know how I ended up here, but I thought this post was good.
I do not know who you are but certainly you are going to a famous blogger
if you aren’t already 😉 Cheers!
Wow! Finally I got a weblog from where I be able to actually take useful information regarding my study and knowledge.
have a nice studying
Saved as a favorite, I like your blog!